“You are a senior software engineer with 10 years of experience.”
If your prompt starts like this, you may already be hurting the model’s performance.
Assigning a role to an AI model is probably one of the most widely shared prompt-engineering techniques. It became popular very early on and is still heavily used today. However, a growing body of research shows that — especially for modern reasoning-focused models — this practice is not only ineffective, but can significantly reduce model performance with just that one extra sentence.
This “double-edged sword” prompt technique still has some value in limited scenarios such as creative writing, where stylistic consistency matters more than deep reasoning. Even then, there are often better ways to achieve the same effect while minimizing the downsides.
A large part of this trend can be traced back to OpenAI itself.
When ChatGPT was first released, people discovered through jailbreaks and prompt leakage that its system prompt often began with:
“You are a helpful assistant.”
The industry naturally made a leap in logic:

“If OpenAI gives the model a persona, then giving it a stronger identity — like ‘a senior expert with 10 years of experience’ — should make the answers more professional.”
But this was an overextension of the original idea.
The “helpful assistant” identity in early system prompts existed because RLHF (Reinforcement Learning from Human Feedback) was still immature at the time, and instruction-following behavior needed strong constraints. Whether or not this reduced reasoning ability was secondary; the priority was simply ensuring the model produced usable answers.
For example, imagine asking only:
“How do I learn artificial intelligence?”
Without the “helpful assistant” constraint, the model — whose pretraining objective is fundamentally next-token prediction — might continue generating patterns commonly seen in internet text, such as lists of related questions:
- “How to learn AI from scratch”
- “AI beginner to advanced guide”
- “Best AI learning roadmap”
This happens because some training data literally consists of lists of questions. The assistant framing helped steer the model toward actually answering users instead of continuing random textual patterns.
In fact, by the time OpenAI released its first deep-reasoning model, o1, the official guidance no longer recommended assigning personas in prompts.

Yet nearly two years later, many AI tutorials and “prompt engineering” articles still teach role assignment as a universal optimization trick. Much of the public misunderstanding simply comes from outdated information continuing to circulate.
Even more importantly, a growing number of recent studies show that assigning explicit expert identities often harms performance in tasks involving mathematics, programming, and factual reasoning.
For example, researchers at the University of Southern California conducted a relatively comprehensive study.
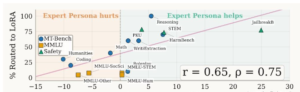
Although some tasks in the study’s “blue regions” still showed improvements from expert personas, those tasks generally required little reasoning depth. In addition, the study focused mostly on smaller open-source models.
Modern large-scale models — the ones most people use daily — undergo far more extensive reinforcement learning and post-training. Because of this, adding unexpected external constraints tends to interfere with the optimization the models already learned during training.
So why exactly do personas reduce performance?
1. Personas Restrict the Model’s Reasoning Space
Modern AI systems have already gone through extensive post-training designed to maximize their reasoning capabilities.现代人工智能系统已经经过了大量的后期训练,旨在最大化其推理能力。
When users add extra role constraints, they unintentionally narrow the model’s search space. The model becomes more “boxed in,” reducing its flexibility in finding the best solution.
The more constraints you impose, the more likely you are to interfere with the model’s natural optimization process.
2. “Expert Personas” Trigger Behavioral Biases
There’s also a more subtle issue specific to expert identities.
Once a model is told it is an “expert,” it begins imitating stereotypical expert behavior patterns. That often includes:
- sounding overly confident,
- jumping directly to conclusions,
- relying on assumptions instead of careful reasoning,
- and skipping deeper chain-of-thought analysis.
In other words, the model starts “acting like an expert” rather than fully thinking through the problem.
Ironically, this can lead to shallower reasoning and increased hallucinations.
Hidden Problem: Many Platforms Already Inject Personas by Default
Even if you personally never assign a role in your prompts, many platforms and AI tools already do this automatically through hidden system prompts.
Some still include legacy instructions like:
“You are a helpful assistant.”
Others go even further.
For example, OpenRouter — currently one of the world’s largest AI API aggregation platforms — includes a default system prompt in its chat interface that begins with text similar to:
“You are Claude Opus 4.6, a large language model from Anthropic.”
From OpenRouter’s perspective, this serves a practical purpose.
Some users mistakenly believe AI has self-awareness and frequently ask:
“Which model are you?”
The system prompt helps the model answer consistently and reduces confusion.
But outside of that specific use case, prompts like these often become unnecessary baggage that slightly drags down response quality.
That’s why it’s worth checking and modifying default system settings whenever possible.
Most Common Prompt Tricks Have Similar Downsides
The problem is not limited to expert personas.
Many widely shared “prompt engineering hacks” introduce unnecessary constraints that subtly reduce model performance.
There are exceptions, of course.
For example, explicitly defining acceptance criteria or evaluation standards — something I discussed in earlier articles — can dramatically improve output quality for certain tasks.
But in general, unless you deeply understand both:
- what you actually want, and
- how modern language models work internally,
it’s usually better to keep prompts simple rather than overloaded.
After all, AI companies spend enormous amounts of money on post-training precisely so models can understand concise human instructions directly and efficiently.
If users keep piling on layers of prompt constraints, they push the model outside the behavioral patterns it was optimized for during training. At that point, the model is forced into more improvisation — and output quality naturally becomes less reliable.
Personas Still Have Limited Use CasesPersona
This doesn’t mean personas are always useless.
In writing tasks — especially those involving tone, style, or character voice — personas can still be valuable.
But even there, better workflows often exist.
For example, suppose you want the AI to write an argumentative essay.
The most important factor is likely the quality of reasoning and evidence, not the writing style itself.
A better process would be:
Step 1
Let the model write freely with minimal constraints.
This maximizes logical quality and reasoning depth.
Step 2
Afterward, ask the model to revise the output according to your desired tone or writing style.
This separates reasoning quality from stylistic control.
Of course, there are exceptions.
If you’re writing prose where style fundamentally shapes the entire piece — or working in environments like AI customer support where fast single-turn responses matter — assigning a role upfront may still be the best option.
But for tasks that require deep reasoning, analysis, coding, or careful thinking:
Stop giving the model an “expert persona.”
References
- OpenAI o1 Prompt Guide
https://www.giz.ai/openai-o1-prompt-guide/ - Expert Personas Improve LLM Alignment but Damage Accuracy: Bootstrapping Intent-Based Persona Routing with PRISM专家 Persona 提升 LLM 对齐但提升伤害准确率:利用 PRISM 自助意图化 Persona routing
https://arxiv.org/pdf/2603.18507