
VLA is dead. Teleoperation is dead too. That is what Nvidia top robotics leader Jim Fan declared.
At the recent AI Ascent 2026 event, Jim Fan took just 20 minutes to shake the entire robotics industry.
This was not his first bold claim. Last year, he stood on the same stage and predicted that VLA would dominate. This year, he started over.
Some say Nvidia is just pushing its own chips. But Jim Fan last year also talked about general AI on the same stage. This year, he is already rewriting the playbook.
Why is the new approach different? And why does the old approach fail?
Here is the new path. Jim Fan says it borrows heavily from the LLM playbook.
Pretrain the model to predict the next physical world state. Use LLM next token prediction.
Then use supervised finetuning to align the valuable parts with real world actions.
Finally, use reinforcement learning to push the model further.

Over the past year, Nvidia has launched EgoScale, DreamDojo, and Dream Zero. These are a series of key projects. And now in 2026, they have all come together.
In this talk called Robotics Endgame, Jim Fan declared war on old ideas. He said VLA models, teleoperation, UMI, egocentric data, and scaling laws are all wrong. And he proposed ten new ideas worth one billion dollars each.
Here are the key points from his talk.
The full talk is worth watching.
But for readers, we have edited it for clarity.
In 2016, one afternoon, I sat in an office in Palo Alto. A Tesla was parked outside. A rocket was growing nearby. And a robot was walking on the road.
Elon Musk and the OpenAI team came down. They showed me a DGX1. It was the first one.
That was my first time meeting Ilya. He was an intern. He signed the receipt with his own hand.
That was my first day at OpenAI. I was there with Andrej Karpathy.

At that time, I did not know what I wanted to do. I was thinking about many things. I could not be as focused as Ilya.
But I was thinking about deep learning. And I was thinking about robots.
Of course, we all know deep learning changed the world. It changed every field.
But at that time, we did not know it would change robotics too.
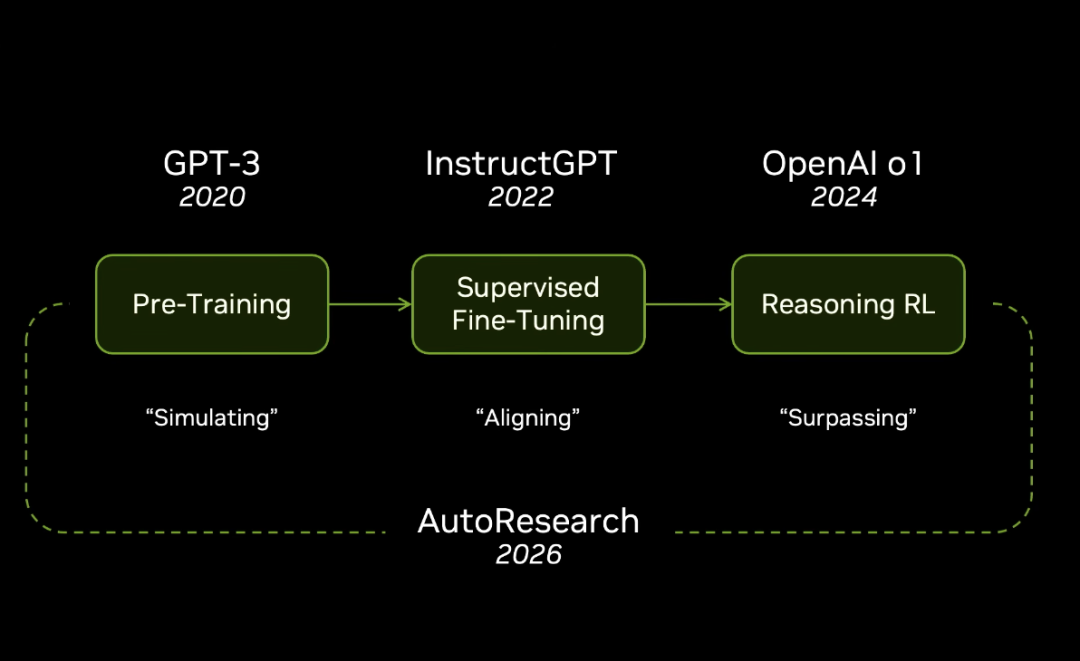
Phase one was 2020. GPT-3 pretrained on next token prediction. It learned grammar. It learned world structure. It learned logic. It learned how to write.
Phase two was 2022. InstructGPT used supervised finetuning to make GPT follow real world tasks. And it used reinforcement learning to push the model further.
Phase three is 2026. Autoresearch is the new loop. It is the next step.
As Andrej said, there is a new project. It is LMS. It is a model system. It is the web stage.
Honestly, I am very close to Andrej. We joke a lot. We are very open.
But when the model team reaches the inflection point, when we are about to hit AGI through human feedback, we call the key moment the mythos.
Why is the robot field also interesting to me?
Because I am a strong scientist. And I like the Great Parallel. It is the parallel between LLMs and robotics.
We do not predict the next token. We predict the next physical world state. Then we use supervised finetuning to align the valuable parts. And we use reinforcement learning to push further.
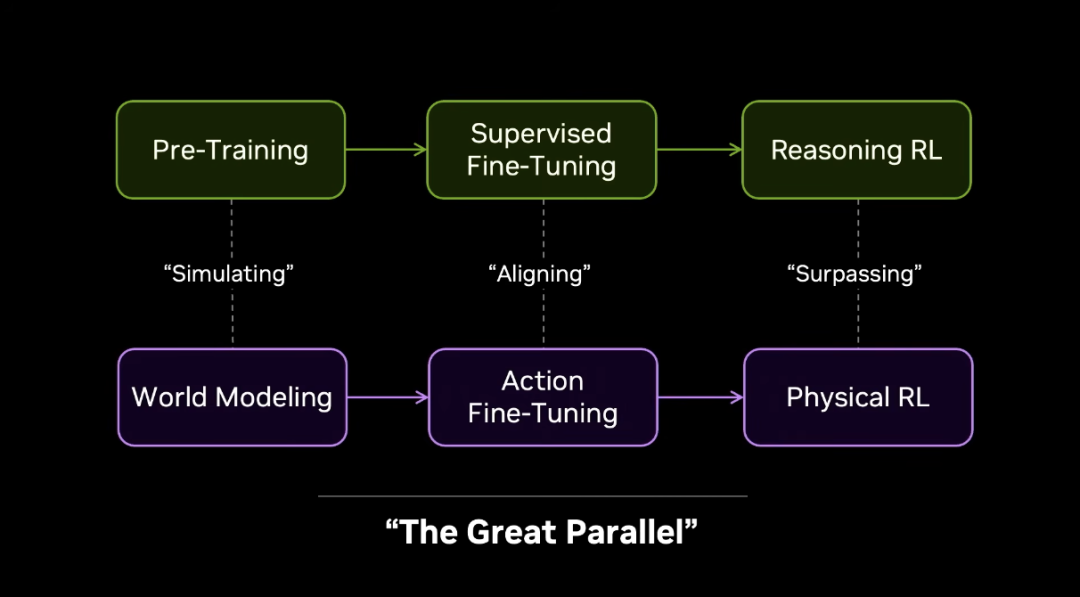
Parallel research is the key to model success. It does not matter if it is text or images.
And now we have reached the endgame. Robotics The End Game.
I could not help but smile. It was too interesting. Thank you all.

Now let me turn to the main point. There are two strategies. Model strategy and data strategy.

First, model strategy. Last year, VLA models like Pi and Gr00t were the hot topic.
They are pretrained VLMs. Then they add an action head.
In fact, most of these models are LVAs. They are language visual action models. Most of them do not really understand vision. They use text as the core. And they graft vision and action on top.
In VLA, language is the main path. Vision and action can only look at text.
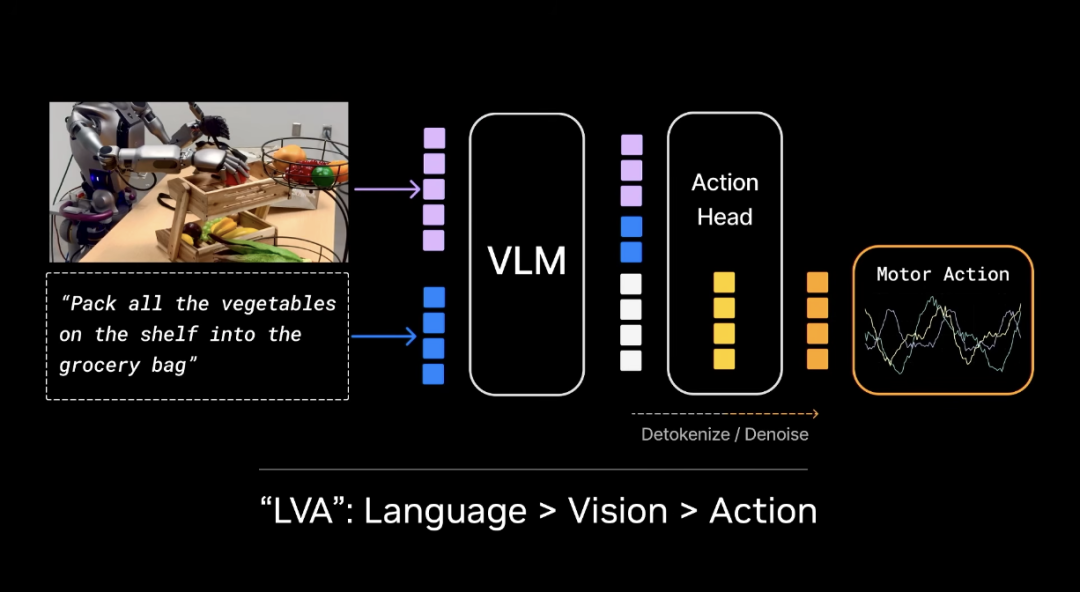
On top of that, VLA has a knowledge bias. It inherits text pretraining. It has investment bias. And it has a head heavy problem.
My favorite VLA example is RT-2. It was trained on Taylor Swift images. And it could not handle new tasks.
But the future needs models that can handle new tasks. And that needs pretraining.

So what is the second pretraining paradigm?
I think the second pretraining paradigm is very important. And the industry calls it AI video slop. It is like cat videos on the internet.
But in fact, these videos have no text labels. They are raw video. The model learns from these videos. It learns the next state.
Take Veo3 as an example. The model learns from video. It learns physics. It learns motion. It learns objects. It has no formal rules. It uses video pretraining. And it learns.

Veo3 learns these videos through physical space simulation. It pays attention to details. It learns physics. It learns motion. I call it physics slop.
These video models learn the possible future states. They compress the real world. They learn the valuable parts.
And that is Dream Zero.

Dream Zero is a new type of model. It does not predict the future. It dreams the future. And then it acts.
You need to know that human motion is very complex. It is high dimensional. It has signals. In some tasks, the data has no labels. But the model learns from the changes.
So we can take a video. And we can also take the motion.
Dream Zero takes the video and the motion. It learns the next state. And it learns the next action.
It can also do zero shot. It can handle tasks it has never seen.
The key idea is when the model starts to execute, it does not know what will happen. But it can react in real time. It is very smart.
Video prediction is right. And inverse dynamics is right. But video is the key. And action is the result.
So we have Dream Zero. We have done many real tests. We put the model in the real world. We gave it prompts. We gave it commands. And we saw what it could do.
And Dream Zero reached 100 percent stable success.
It is like GPT-2. It is not perfect every time. But it has the spark. It has the potential.
Dream Zero is the first model with open ended prompting. And open vocabulary.
From this moment, we call the new model World Action Models. Or WAM.
And from this moment, we call the old model the VLA default.

The best part is the upgrade path. VLA to VLA plus. And VLA plus to WAM.
To make WAM work, we need a new data strategy.
Bill Dally said we need real data. And we need teleoperation.

But we need to be honest. Teleoperation is the old way. It is the golden age of teleoperation.
Last year, teleoperation was the standard. VR headsets, haptic systems, and complex setups. Each robot needs one human. And one human can only control one robot.
The data is limited. And it is expensive.
In theory, one human can control one robot for 24 hours. But in reality, each robot is stable for only 3 hours. And that is already good.

Before this, we had the imitation learning era. But these companies failed. Because they could not scale.
So we need a new way. We need more data.
The old way puts humans in the loop. Humans control the robot. And the robot learns.
UMI is the universal manipulation interface. It is a general interface.
The idea is simple. Put a camera on the hand. Let the robot copy the hand. But this is hard. Because the robot and the human are different.
In short, UMI is one of the best ideas. But it is only one tenth of the solution.

On the left is the Generalist team. They put a camera on the hand. And they collect data.
On the right is Sunday. They use exoskeletons.
Last year, a company launched an exoskeleton system. It maps hand motion 1 to 1.
It is called DexUMI. It works.

On the left, the traditional way also uses data collection. But it is remote. And it is slow.
On the right, teleoperation has many problems. It is hard to scale. It is expensive. And it is slow.
So we need a new way. We need to put the human in the data. But we need to use the data differently.
Our method is simple. We do not need to put a camera on every hand. We just need to use the data we already have.
We use human egocentric videos. These are videos from a human point of view. And they are everywhere.
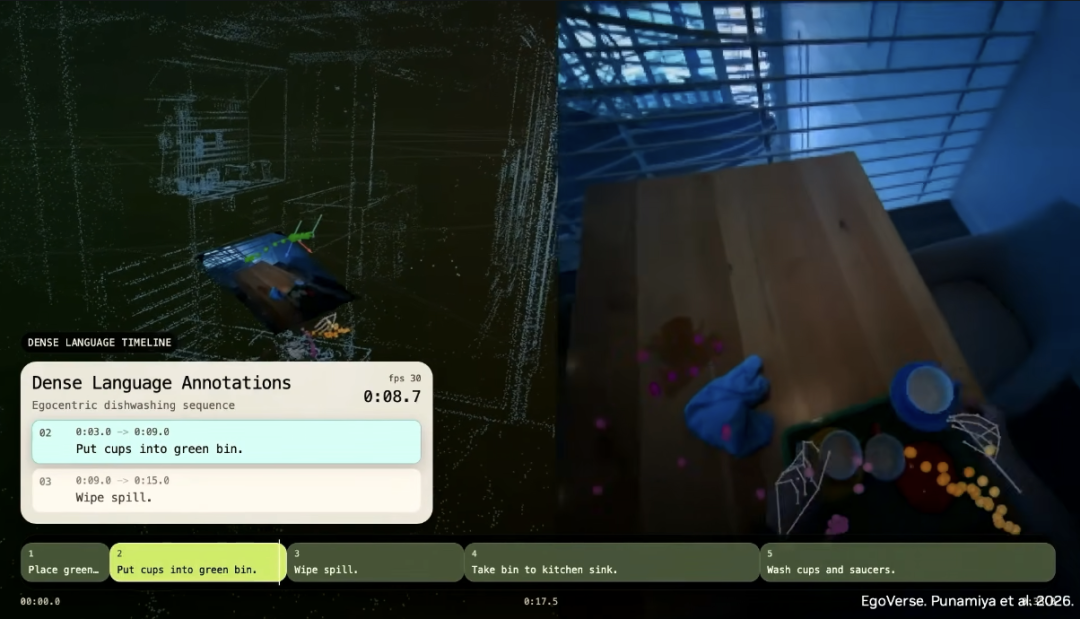
We call this EgoScale. In EgoScale, 99.9 percent of the training data is human egocentric video.
The result is an end to end humanoid model. It can directly take video input. And it can map to a 22 degree of freedom robot hand. In short, from video to hand.
And this is a fully generalist robot.

In the pretrain stage, EgoScale uses 2.1 million hours of real human video. No robot data. Just human video.
The model learns to predict hand position and object state.
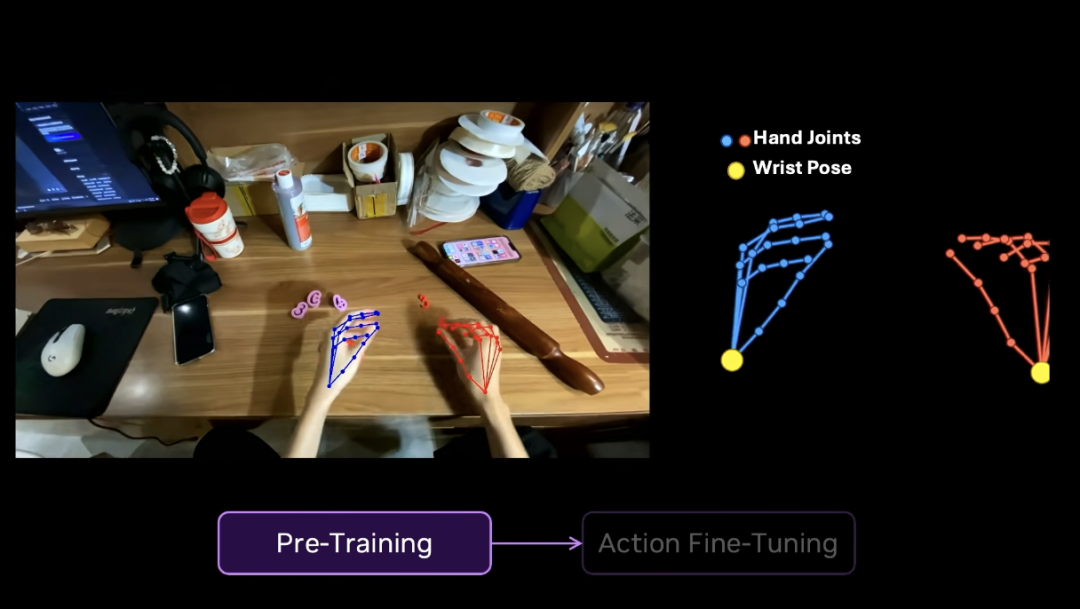
In the motion finetuning stage, we only use 50 hours of high quality human video. And 4 hours of robot data. That is only 0.1 percent of the training data.

With EgoScale, the model can handle many high degree of freedom tasks. It can open bottles. It can pour water. It can fold clothes. And it can write.
The key idea is that we only need one demonstration. And the model learns a new task.
In this paper, we found something exciting. We found the scaling law.
We found a log linear relationship between pretraining time and validation loss.
cumshot ai
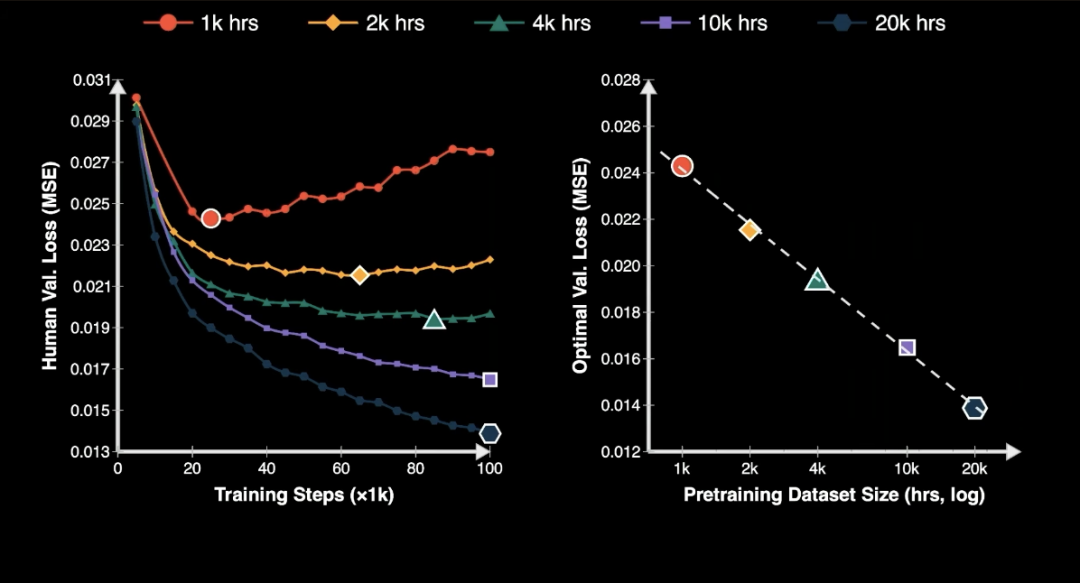
This is the first time we found the neural scaling law for robotics.
Before, robots had their own scaling law. We plot data on the X axis. And we plot performance on the Y axis.
undress ai tools
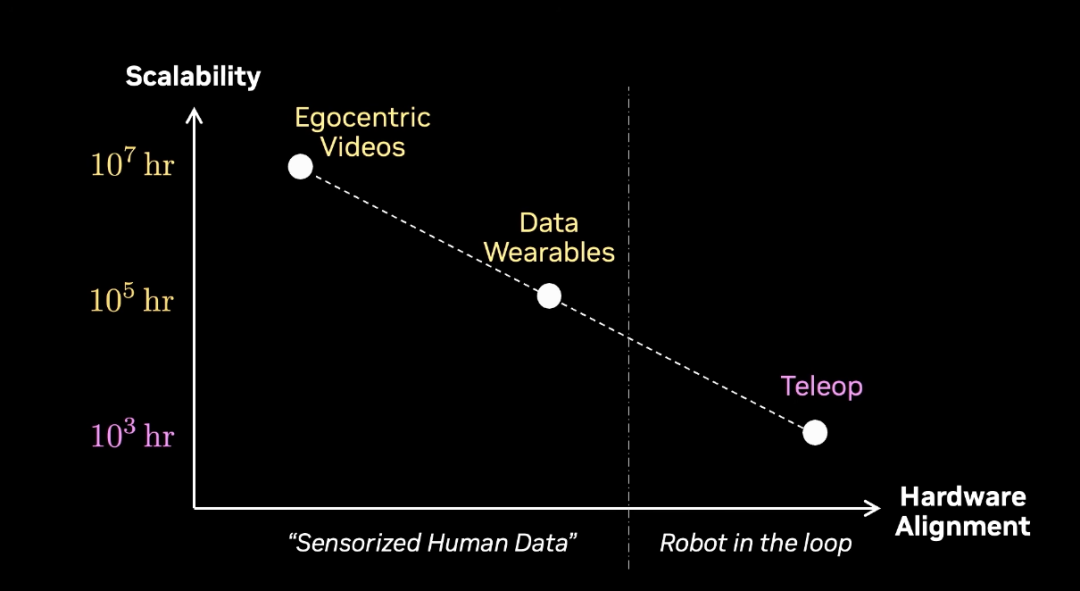
But the problem is teleoperation. Teleoperation is the bottleneck.
On the hardware side, one device can only collect 10 hours of data.
On the human video side, one human can collect thousands of hours. Just by living.
On the graph, one line is hardware data. And one line is human video data. We call this sensorized human data.
So we can predict the future. In one year, teleoperation will be less and less. And human video will be more and more.
But we need different hardware. We need different devices. We need different video collection tools.
Today, one human can collect one hour of video per day. Just by living.
So we declare teleoperation the default.
 clothes remover
clothes remover
The best part is the upgrade path. Teleoperation is the old default. And human video is the new data source.
For data strategy, the old way is dead. And the new way is here.
Have you noticed one thing? Why is the robot field different from the LLM field?

Today, we have deep reinforcement learning. We have simulation. And we have RL.
But in the real world, RL is hard. It is slow. And it is expensive.
Of course, we can do RL in simulation. And we can get close to 100 percent success.
But in the real world, we need to install GPUs. We need to run tests. And we need to wait.
One person said good boi. And the robot passed the test.

But the problem is that even big models need RL. And RL needs scale. And scale needs data. And data needs money.
Because if you have 100 robots, and each robot costs 100 thousand dollars, and you need 100 robots, the cost is huge. And it is not realistic.
So we need a new path.
For example, we only need an iPhone. We take a video. And we build a 3D world scanning pipeline. The system auto recognizes the scene. It gets the 3D structure. And it trains the model.
The key is that these scenes are not static. They are dynamic. And they are real.
We call these digital cousins.
With one iPhone, one person can scan one room. We call it real sim real.
The idea is simple. Go to the real world. Scan the scene. Go to simulation. And go back to the real world.
This is the flywheel. It is the loop. It is the data engine.
And this is how we scale.
But how do we get the model?
We use Dream Dojo.
Dream Dojo is a world model system. It is built on video. It learns from video. And it learns from action.

In this model, we can see RGB video. And we can see the action state. All in real time.
In short, in the robot world, nothing is static.
Dream Dojo learns through a new method. It learns from different human motions. It learns from different tasks. And it learns without any labels.
So we have a new post training method.
In the real world, we collect data. We collect high value data. We use graphics cores. We use world scans. And we use RL. All to train the model.
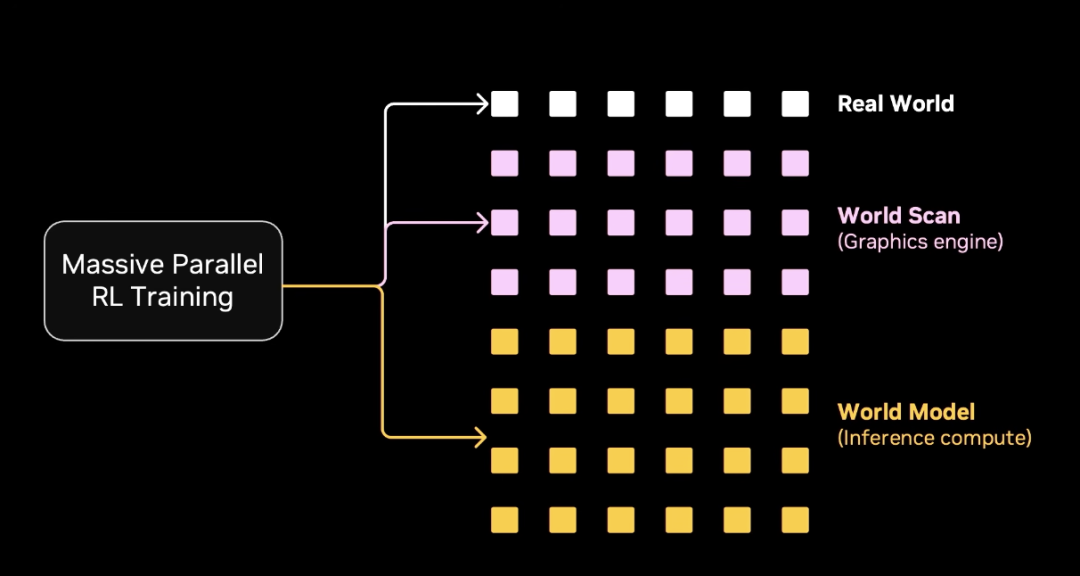
In this new path, one thing is key. Compute equals data.
That means if you have compute, you have data. And if you have data, you have flywheel. And the flywheel makes the model better.
Jim Fan left with a smile. He said the more data, the more compute, the better. And that has been proven.
But one thing we found is that the model needs a new architecture. It needs a new training path. And it needs a new data source.
And this is the endgame. This is the robotics endgame.
I have always liked comics. And I like research. I like technology. And I like the endgame.
In the Marvel universe, Thanos has the stones. And he has the glove. He only needs one snap. And half the universe is gone.
One snap. And the VLA default is gone.
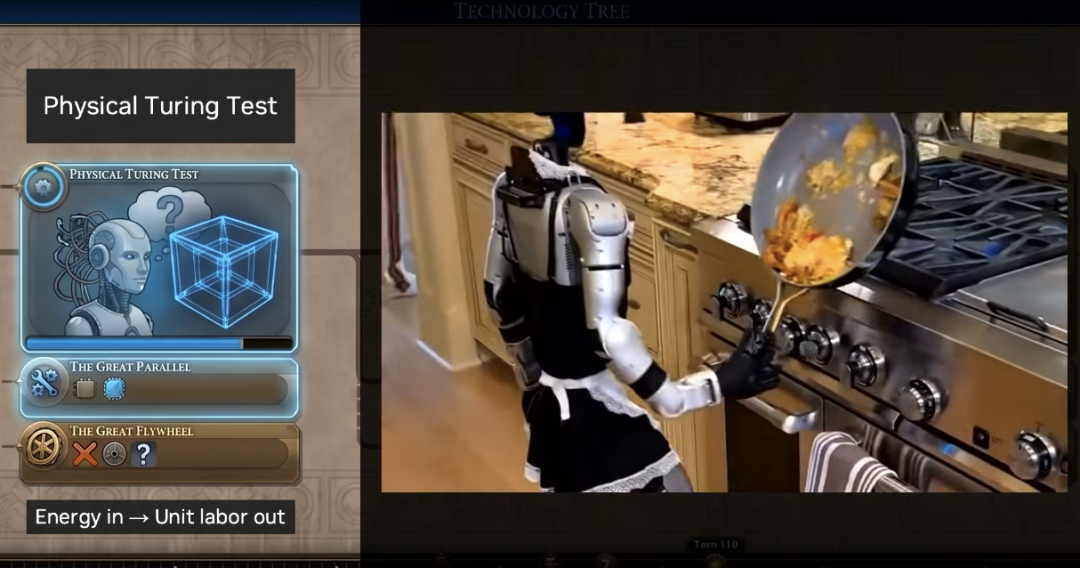
What is the endgame? It means we have enough data. We have enough compute. And the model is so good that we cannot judge it by looking. We need to test it.
In the end, it is all about data and compute. As long as we have both, we can get the same results. And we can get the same value.
But the robot field is different. The robot field has hardware. And the robot field has dynamics. And the robot field has many things that need to work together.
The second snap is the Physical API.
In the future, robots will have hardware. They will have arms. They will have legs. They will have wheels. They will have tools.
But the hardware is not just one robot. It is one robot. Or it is many robots. And the way we control them is through APIs. And CLI. And logic systems.
One day, one agent will control all robots. It will be like Opus 4.6. It will be the generalist.
One Physical API. And many robots. They will work together.
We call them lighthouse factories. They will have robots. They will have 3D printers. They will have CAD. They will have files. And they will have markdown. And they will make real products.
And wet labs. They will do chemistry. They will do biology. They will do drug discovery. And they will do science.
And the third snap is Physical Auto Research.
One day, robots will not just execute. They will think. They will optimize themselves. They will test themselves. They will learn. And they will improve.
At that point, we do not need humans. The robots will do it all.
From 2012 AlexNet to today, it has been 14 years. And we are at the agentic AI moment.
From 2026 to 2040, it will be another 14 years. And we will be at the robotics moment.
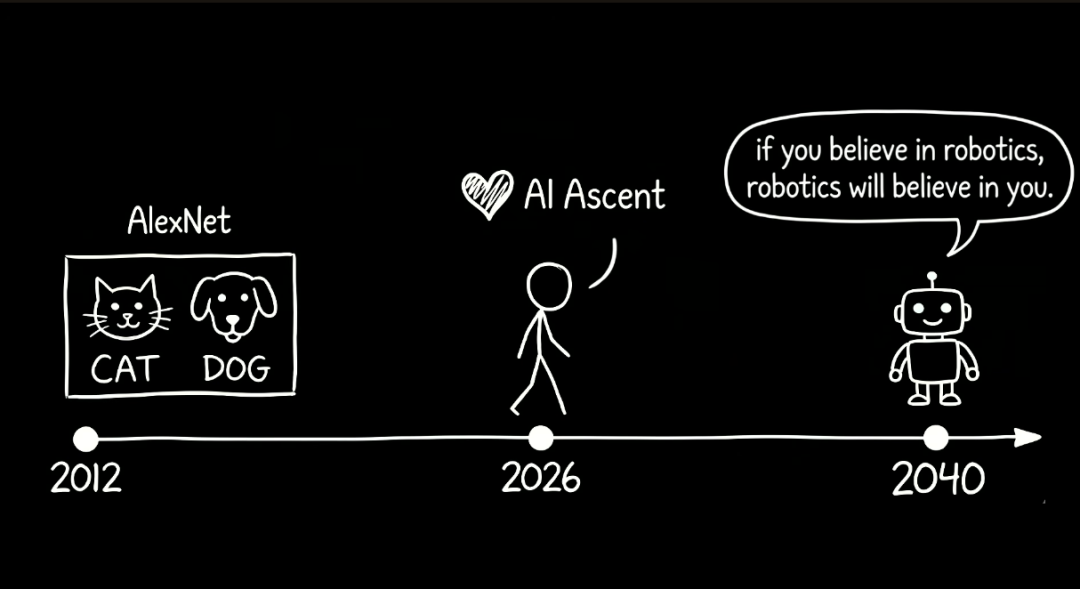
So I believe that 95 percent of houses will have robots before 2040. And they will be at the tech singularity.
And when that day comes, we will be ready.
Our job is not to be too early. And not to be too late. We need to be just right. We need to be at the inflection point. Because that is when we win.



