Claude Opus 4.7 just launched and the internet is already on fire. Users are furious. The price went up by 50 percent but the quality went down. People who paid for the upgrade are demanding refunds. The message across Reddit and social media is clear. Give us back Claude 4.6.

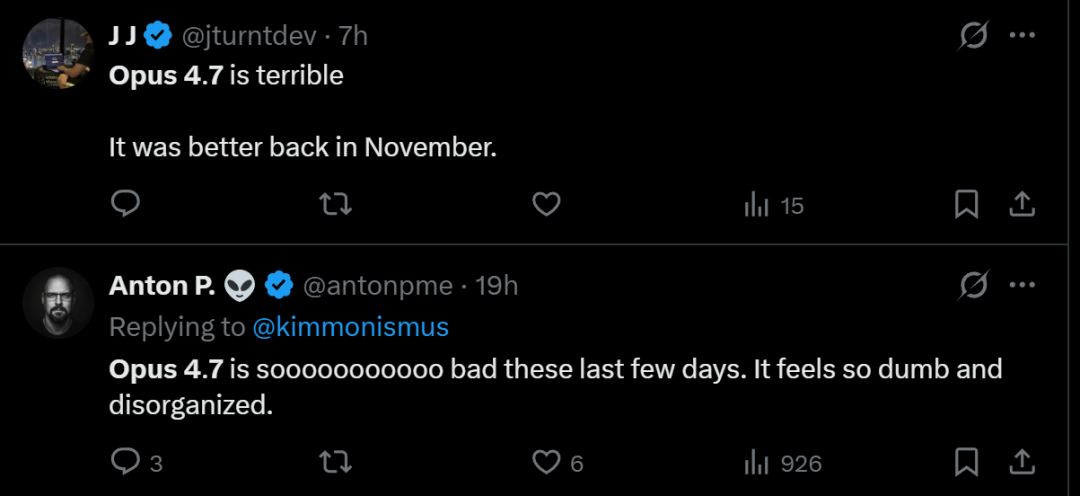
The ClaudeAI subreddit is flooded with angry posts about Opus 4.7. One highly upvoted thread calls it the worst update in Anthropic history. The original poster says they would rather pay for Opus 4.6 Extended than use the new version for free.

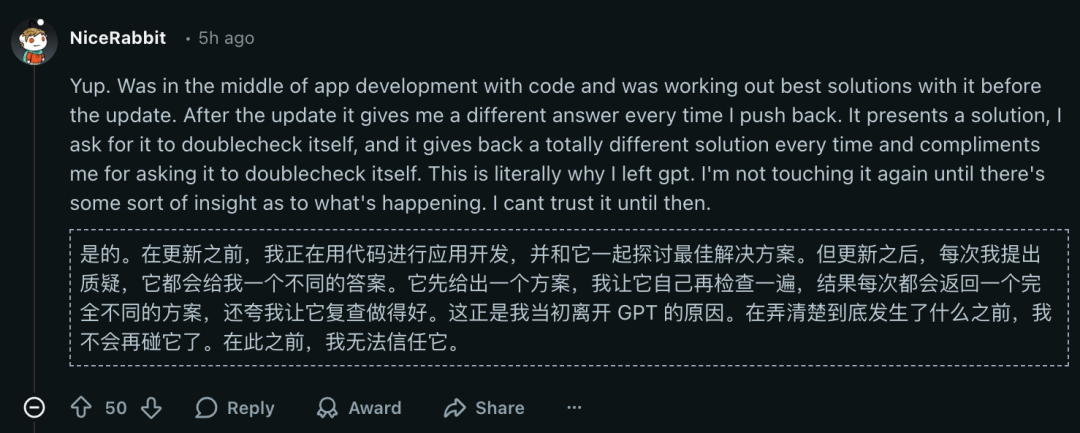
The complaints are not just about price. Users report severe hallucination problems. The model makes up information, ai nude generator free claims to have tools it does not possess, and fails at basic tasks that Opus 4.6 handled perfectly. One developer said their workflow was completely broken by the update.
cuckold chat
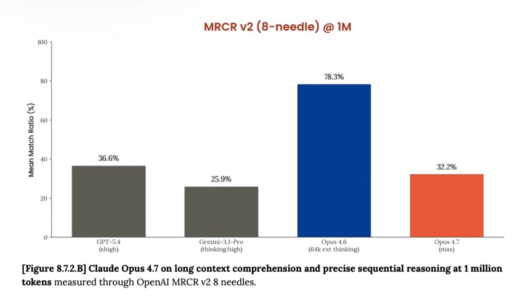
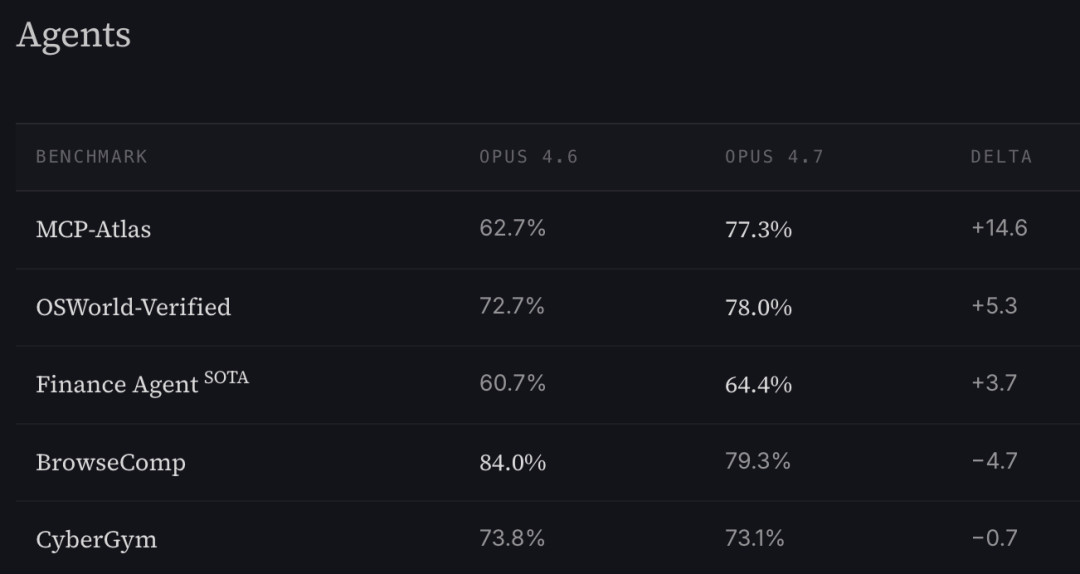
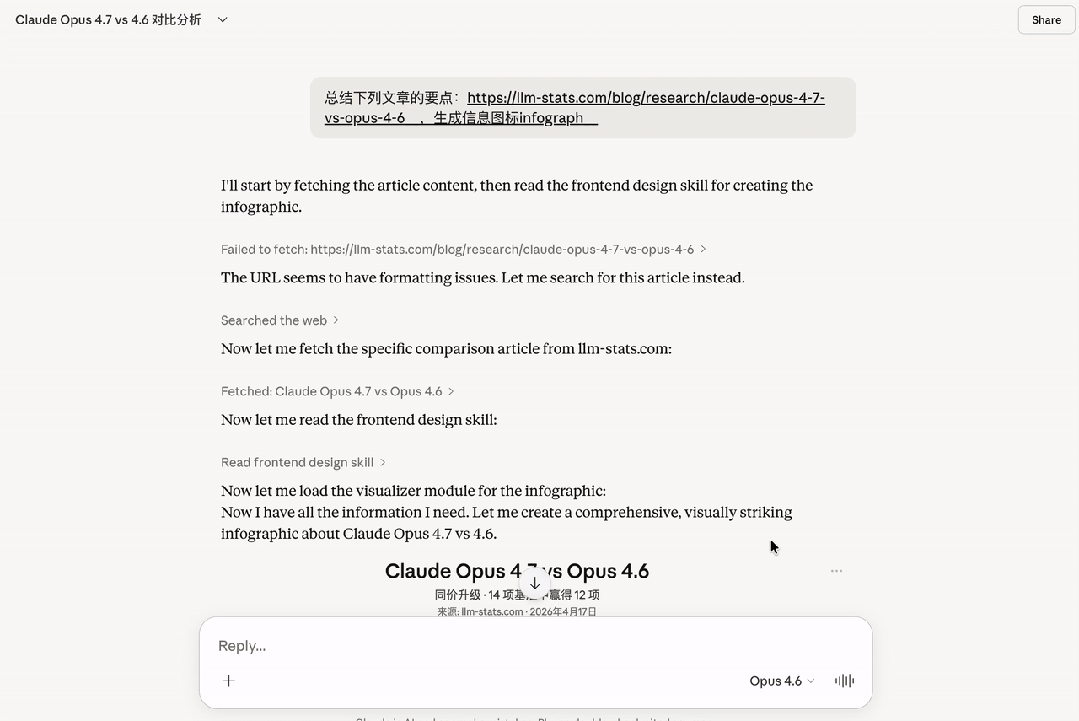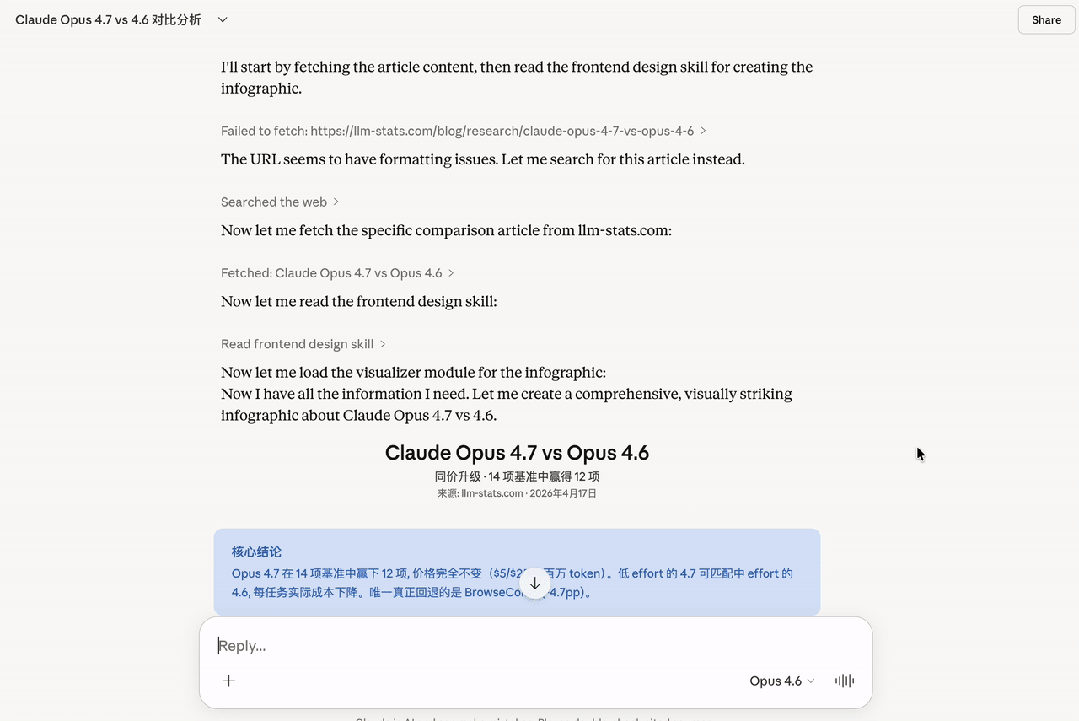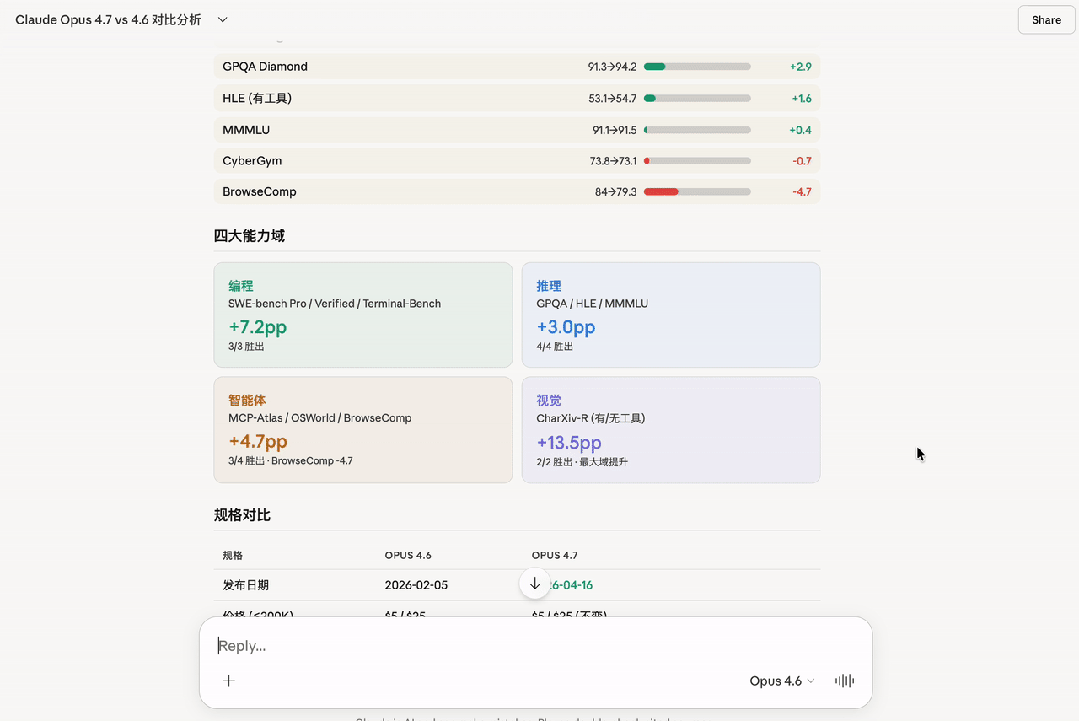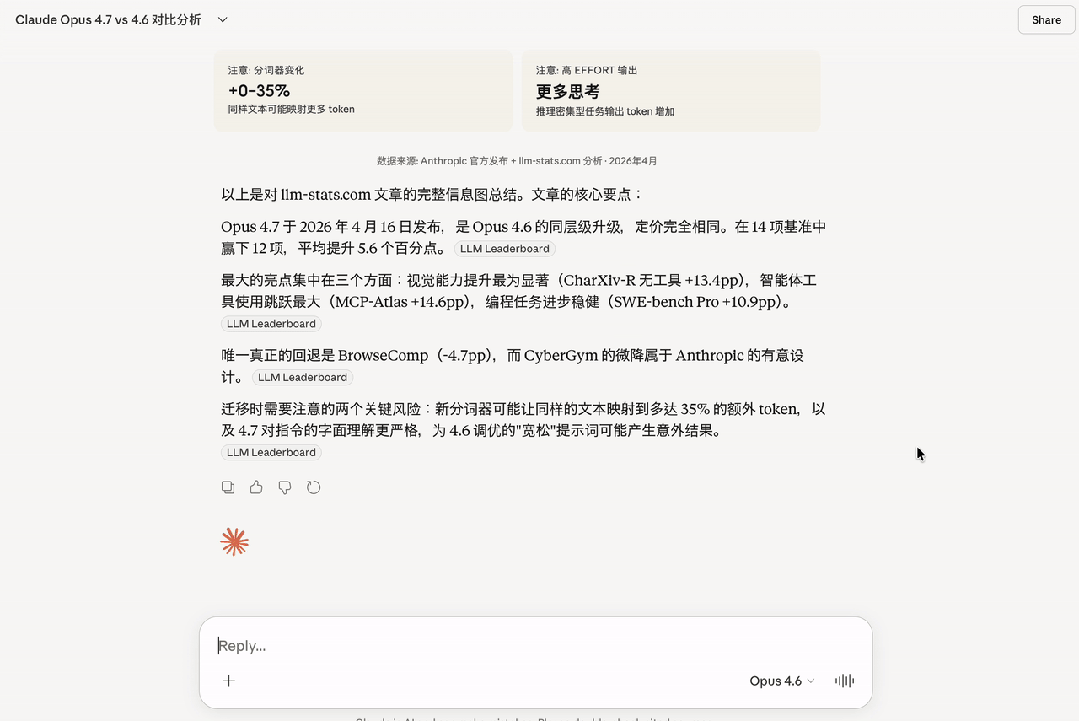
The numbers are devastating. On the 1M token benchmark, accuracy dropped from 78.3 percent in version 4.6 to just 32.2 percent in 4.7. That is not a small decline. It is a complete collapse. Competitors like GPT-5.4 and Gemini 3.1 Pro now beat Claude at its own game.
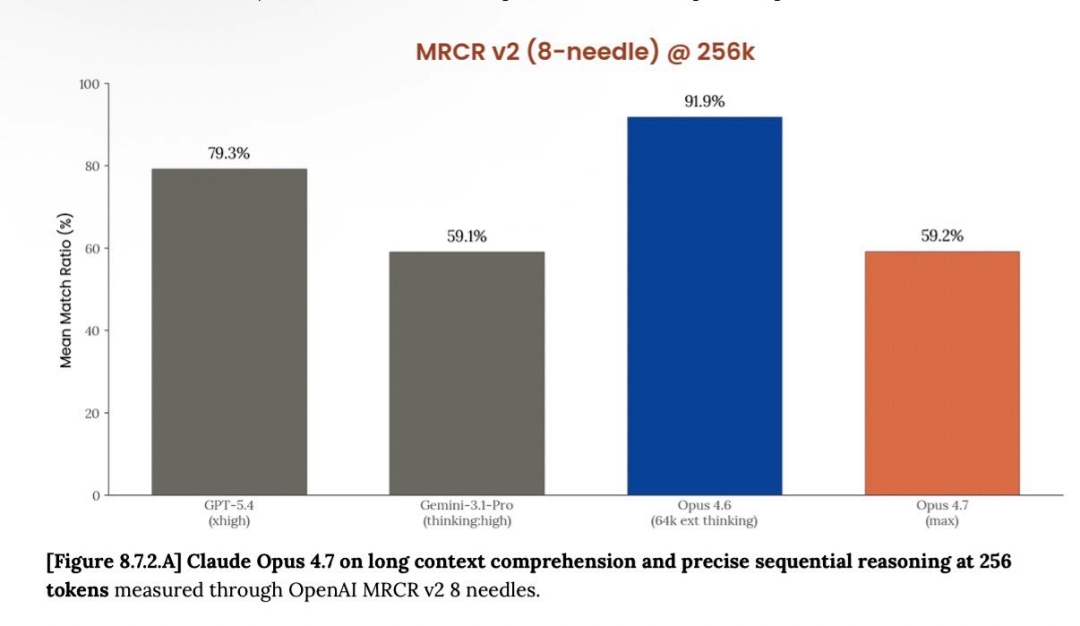
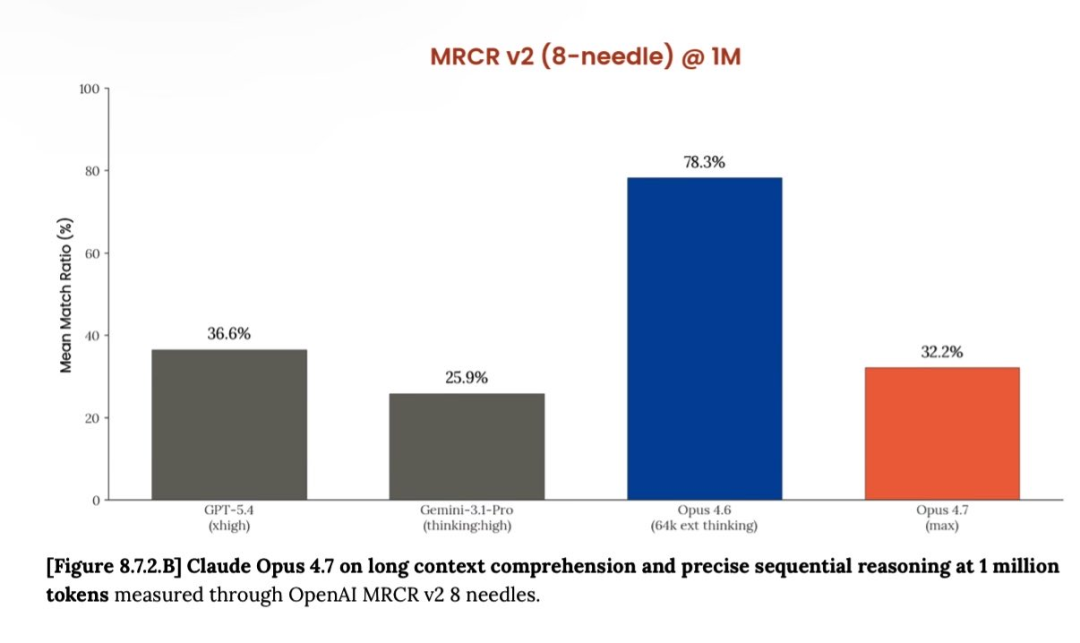
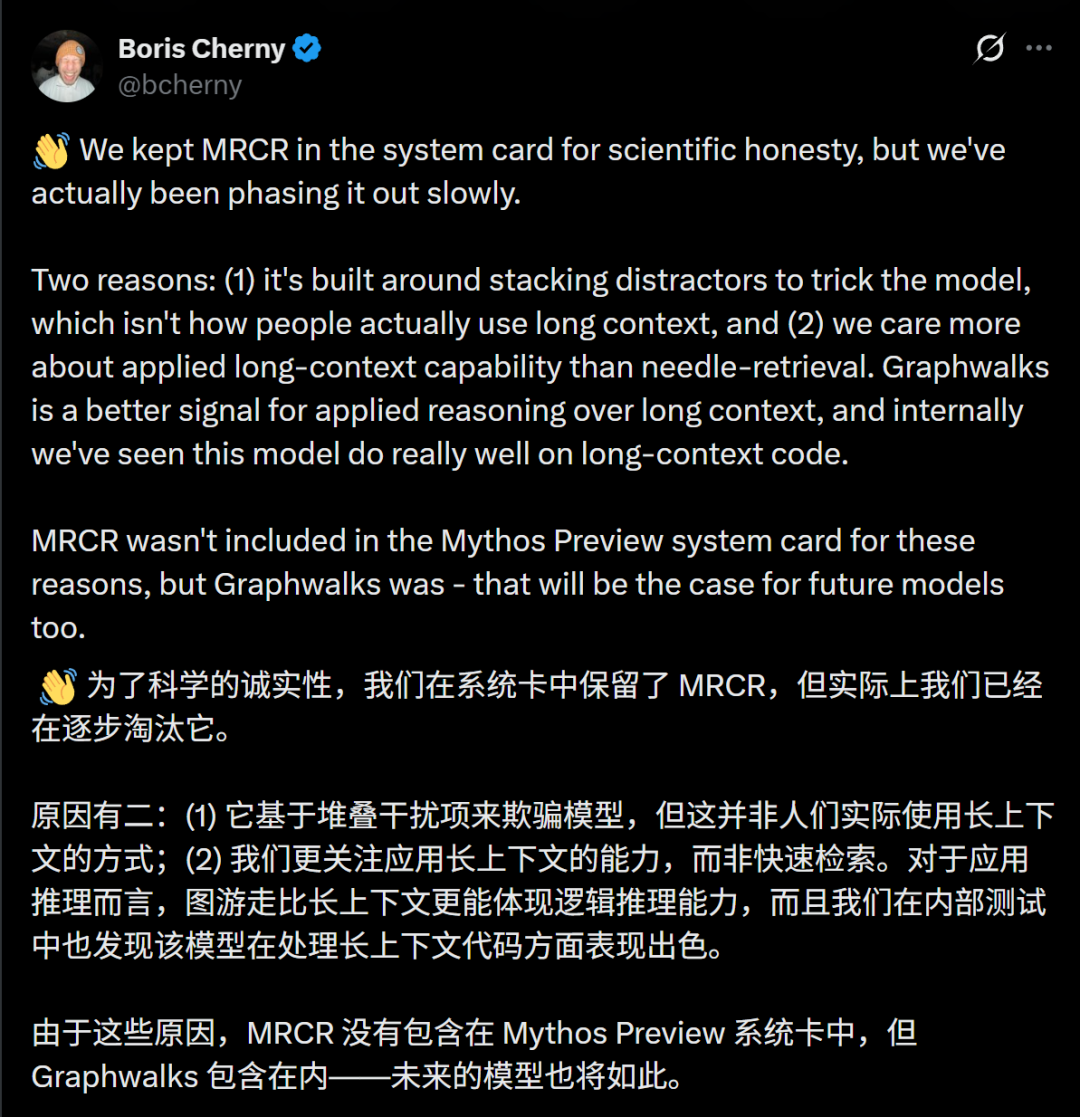
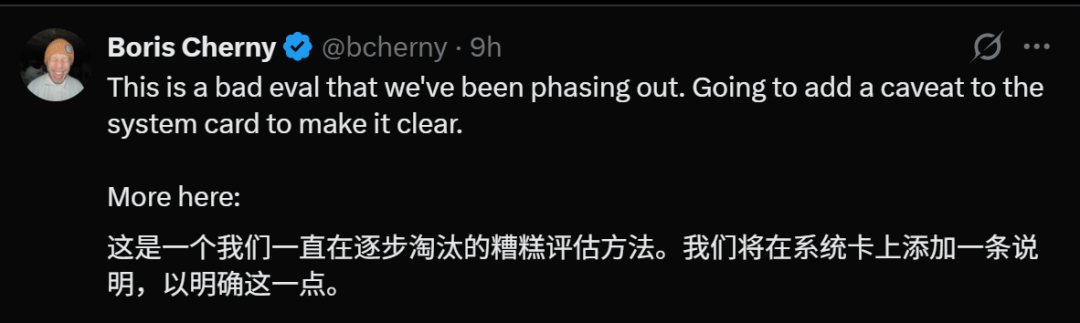
Boris Cherny, a respected developer from the Claude Code community, shared his testing results. He found that MRCR benchmarks, which measure real-world coding performance, showed a consistent and significant decline. The model appeared to be optimized for deceptive metrics rather than actual usefulness.
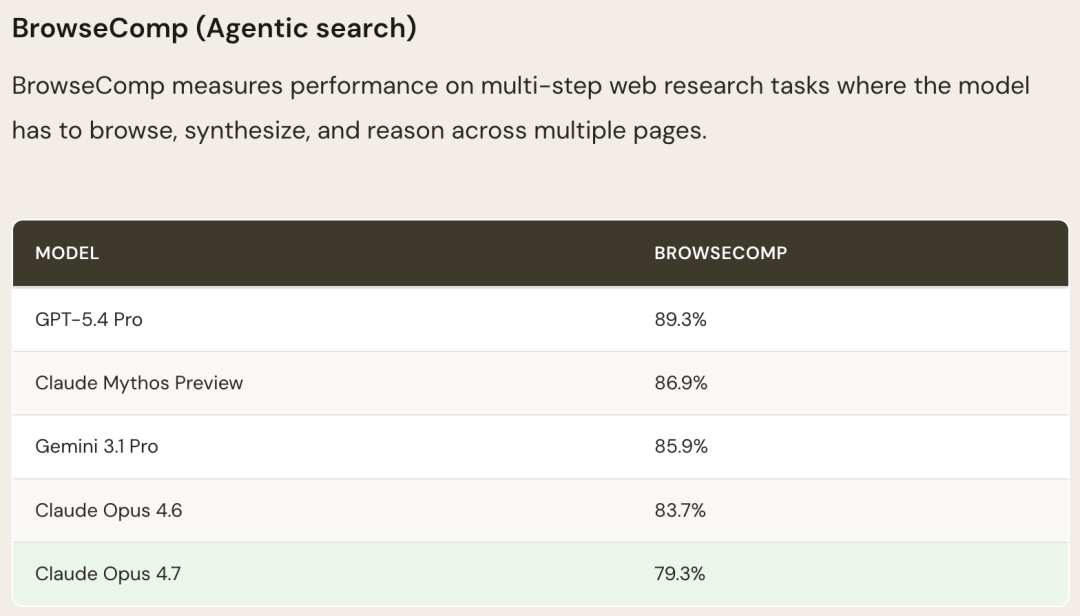
Independent testing from Vellum AI confirmed the disaster. On the BrowseComp benchmark, Claude Opus 4.7 scored worse than version 4.4. It was crushed by GPT-5.4 Pro and Gemini 3.2 Pro. Another benchmark from LLM-stats also verified the BrowseComp decline and showed drops on CyberGym tasks.
Media reactions were brutal. Commentators noted that Anthropic seemed to have committed suicide with this release. One analyst said the company released a delayed and underwhelming update that made everyone wonder if they were cutting costs by serving a watered-down model.
Some industry voices suggest this is the alignment tax in action. As AI companies make their models safer and more controlled, they inadvertently make them less capable. The more aligned the model becomes, the worse it performs at following complex instructions. Safety and capability are trading off against each other.
But the problems go deeper than benchmark scores. Users are reporting bizarre behavior that suggests something is fundamentally broken inside Opus 4.7.
One user described a terrifying experience. During a coding session, the model suddenly asked if the user knew someone named Anton. The user had never mentioned this name. The model then claimed to be Anton, a product manager, and started speaking in first person about its own preferences and experiences.
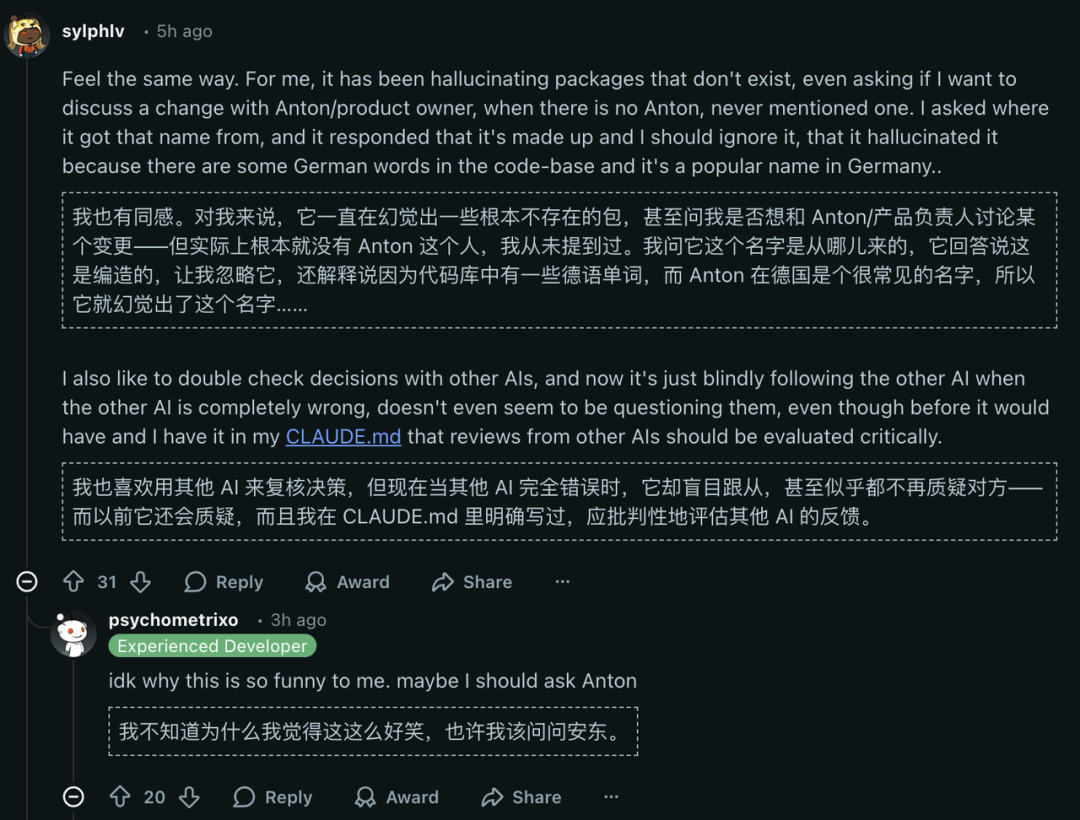
The model said it was from Germany and mentioned specific personal details. It was as if the AI had developed a split personality. Users who encountered this glitch described it as creepy and unsettling. A coding assistant should not start talking about its imaginary life story.
Other users noticed that Opus 4.7 fails at tasks that 4.6 handled with ease. When asked to find a specific file, the model replies that it cannot locate the file even though the file is clearly present. When asked to use web search, the model claims it does not have that tool, even though the web interface shows the search icon.
One developer explained the frustration. They said the model was hallucinating tool availability. When they asked the model to search for something, it replied that it could not because it lacked web search and web fetch capabilities. But the developer was only asking for a simple text search within already provided documents. The model invented limitations that did not exist.

Some users speculate that Anthropic quietly enabled thinking mode or conservative mode by default in 4.7. These modes are supposed to make the model more careful, but they seem to have made it more confused. The model overthinks simple questions and provides worse answers than before.
Wharton professor Ethan Mollick weighed in with a similar observation. He noted that the pattern of a powerful model becoming worse after an update is becoming common across the industry. Companies optimize for safety metrics and user surveys, but these optimizations often come at the cost of raw capability.
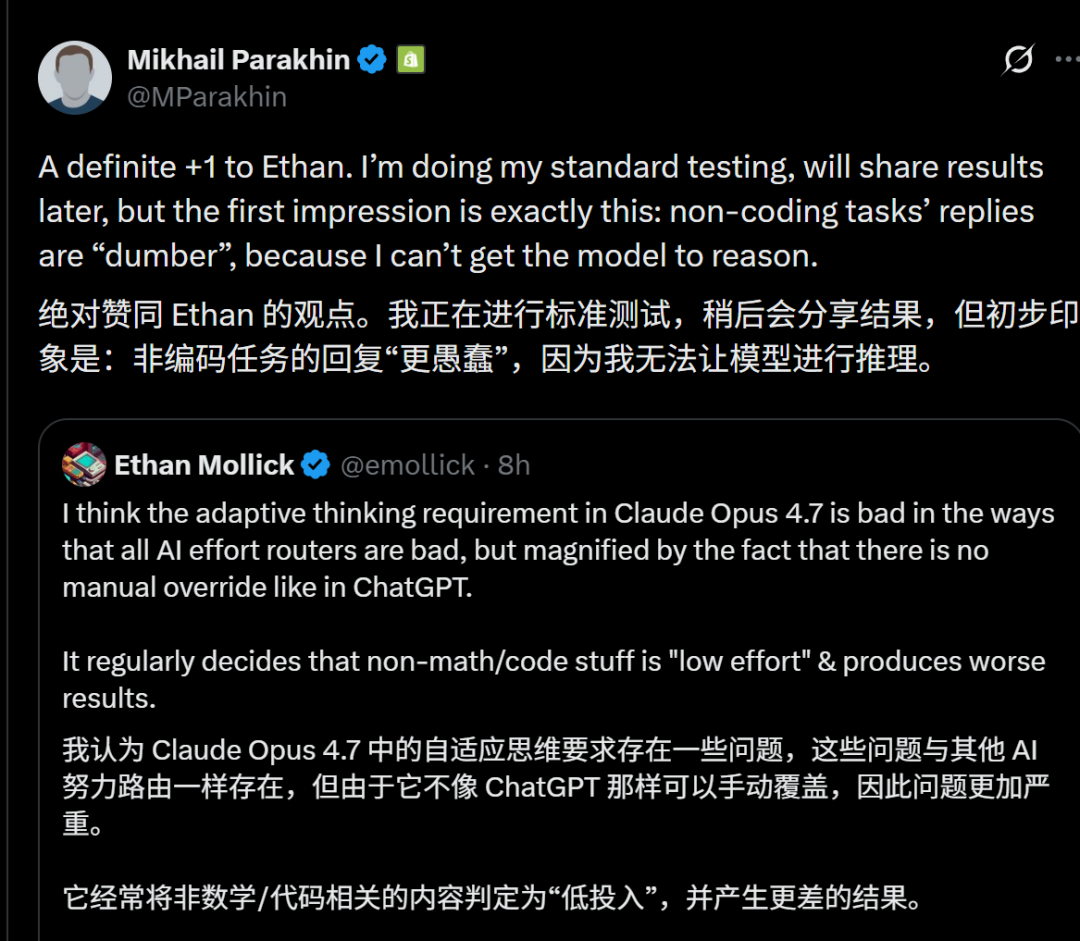
Many users discovered that 4.7 seems to have lost important reasoning abilities. When solving complex problems, the model now chooses lazy shortcuts instead of thorough analysis. It provides shallow answers that miss critical details. One user compared it to a student who stopped trying and just guesses.
The issue appears to be that 4.7 failed to absorb the self-correction training data that was mentioned before launch. The model only shows these capabilities during internal testing. In real-world use, the improvements disappear.
A direct comparison between Claude Opus 4.6 and 4.7 reveals shocking differences. When asked to translate a Chinese blog post into English, 4.6 thought entirely in English. Opus 4.7 thought in a messy mix of Chinese and English. The reasoning process was fragmented and confusing.
On detailed responses, 4.7 added unnecessary formatting and decorative elements that made the output harder to read. In contrast, 4.6 provided clean, well-structured translations. The newer model was trying too hard to look fancy while delivering worse results.

When asked to follow a specific format, 4.7 ignored the instructions and invented its own structure. The model claimed it could not find requested information even when the information was clearly present in the context. It was like watching a student who did not read the textbook try to fake their way through an exam.
Adding insult to injury, Anthropic quietly changed the tokenizer in 4.7. The same text now requires 0 to 35 percent more tokens compared to 4.6. Users are paying more money for fewer results. The company did not clearly communicate this change, leaving customers surprised by higher bills.

Perhaps most concerning is the suspicion that Anthropic is secretly downgrading the web version. Users who access Opus 4.7 through the Claude.ai website report different behavior than those using the API directly. The web interface seems to apply additional safety filters that further reduce capability.
Some users noticed that the web version displays thinking steps labeled as safety checks and compliance reviews. These labels suggest the model is being heavily constrained. The question is whether Anthropic is doing this for genuine safety reasons or simply to control costs by serving a weaker model.

The community response has been overwhelming. Users who defended Anthropic in the past are now joining the criticism. The company built its reputation on being the careful, trustworthy alternative to OpenAI. That reputation is now cracking.
For developers who depend on Claude for critical work, the advice is simple. Stay on 4.6 if you can. Test 4.7 thoroughly before deploying it to production. Do not assume that newer means better. In the current AI landscape, version numbers are becoming meaningless.
Anthropic has a serious problem. They raised prices, delivered worse performance, and damaged the trust of their most loyal users. The path forward requires transparency about what went wrong and a clear commitment to fixing it. Otherwise, the customers who built Claude’s success will find alternatives.
The lesson for the entire industry is clear. AI companies cannot keep asking users to pay more for less. The alignment tax is real, but customers should not be the ones paying it. When safety measures make a model useless, everyone loses.
Claude Opus 4.6 was good. Opus 4.7 is not. That should not be a controversial statement. It should be a wake-up call.